How to run a Digital Platform at Scale
- 11 minutes read - 2228 wordsThis post peels back the covers on what it is like to work with a large digital platform. The platform in question is MDTP - Multichannel Digital Tax Platform, which supports a UK-based tax collection agency which is using a hyperscale cloud provider with a sideline in books.
I’ve previously described what it is like to work in MDTP (Making Software. Quickly) during the Covid-19 responses that allowed the UK government to provide financial support for millions turning around projects in record time. This was made possible because MDTP is a gem of a digital platform.
What is a Digital Platform?

The Equal Experts Digital Platform Playbook defines a digital platform as
a bespoke Platform as a Service (PaaS) product composed of people, processes, and tools that enables teams to rapidly develop, iterate, and operate Digital Services at scale.
What that means is that rather than each service team creating and managing its own infrastructure, you invest in a team (later teams) that will build or buy the tools and processes required so that service teams can concentrate on building value with their services and not spend time constantly reinventing the wheel.
I don’t want to reiterate the points made in the playbook, but for one thing: not everything needs a digital platform as it is a big investment - but when operating at scale, I think it is immensely valuable.
Opinionated Platform: Essential at Scale
The next important point is that in order for a platform to be able to be managable at scale, it needs to be opinionated. What does that mean? Following on from the Netflix paved road a platform must make it easy to:
- Reduce boilerplate (not every service should be implementing their own logging or metric code)
- Provide tools to do it yourself - if every service team needs to raise a ticket to request a new build pipeline, the platform team will soon drown in support work. You Build it, You Run it is essential for a platform team to be able to deliver value without regressing into a traditional Ops role.
- Realise a platform is not a purely technical thing, but a collection of lots of people that are working together to create value. As such, facilitating easy communication should be high on the priority list of a digital platform. Personally, I find Slack a good tool, but at scale can often create a big channel sprawl, so it is crucial to provide help to find the right teams in the right channels.
A bit more background on MDTP on this excerpt from the DevOps handbook: Saving The Economy From Ruin (With A Hyperscale PaaS) At HMRC
Catalogue on MDTP: Helping teams since 2016
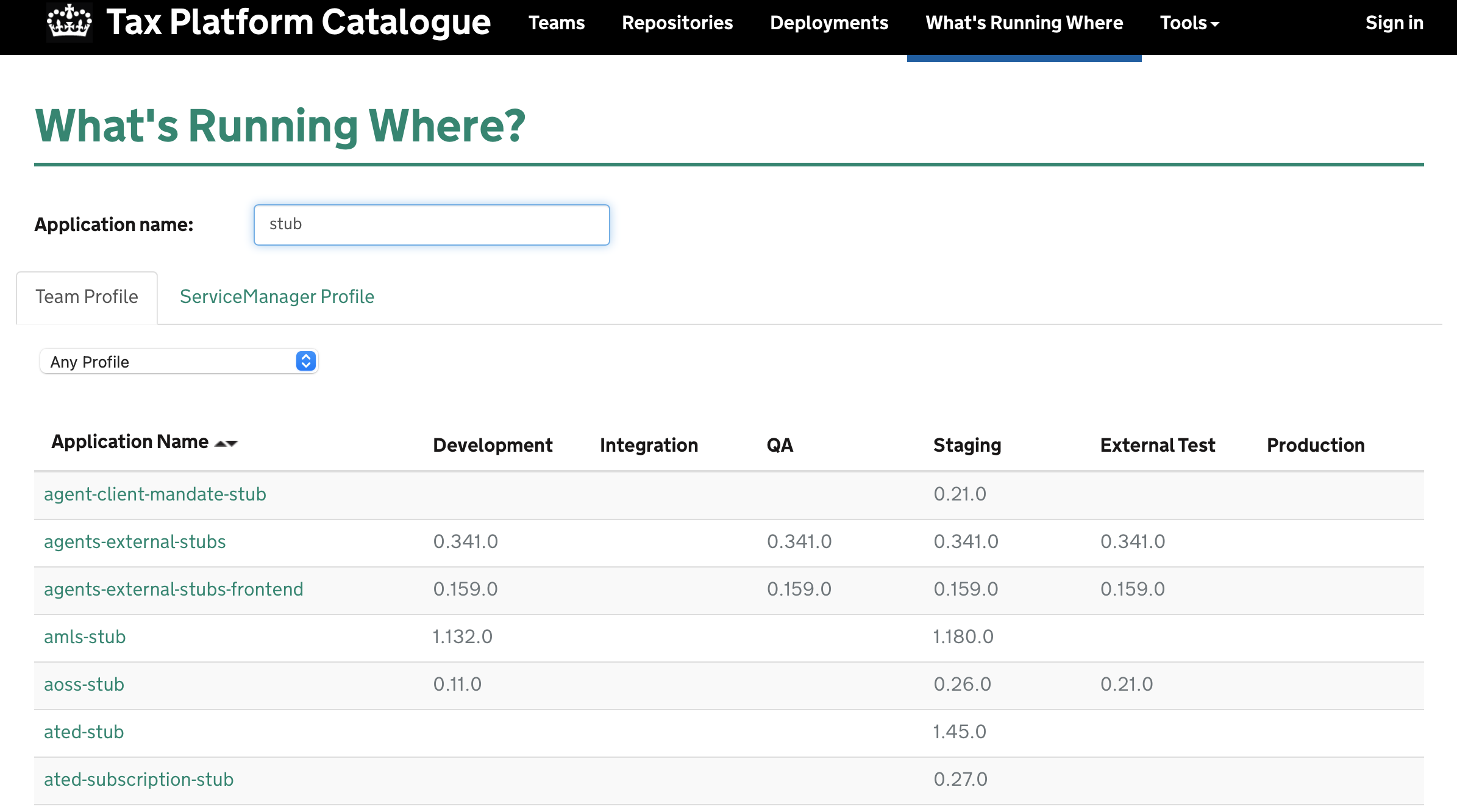
One of the best things about working on MDTP (and I’ve seen this both from the perspective of a service team as well as a platform team) is the catalogue. It is a window into more than 1,000 microservices running on the MDTP platform, which are built by about 100 teams across 10 digital delivery centres (but who’s counting at a time of remote working) The catalogue keeps track of:
- Contact information about teams, services and repositories - with over 4,000 GitHub repositories it’s not an easy task to figure out who is looking after what.
- What versions of services are running in which environments
- Who deployed what when
- Direct, transitive and banned dependencies
- A team’s services, repositories, prototypes and libraries
- Ability to find which microservice belongs to which URL
- Shutter services: temporarily take them offline with a custom message
- Leak Detections: have secrets been leaked into GitHub
- Health Indicators and Platform Initiatives: scores services against metrics such as build stability, stale branches, leaks, out of date libraries - a sort of system of nudges to encourage “good behaviour”
- Cost Explorer: Keeps track of an estimate cost based on the number of running instances of a service in the different environments.
The catalogue is developed by the Platform Operations team (PlatOps). PlatOps provide the tools and paved road for the service teams - libraries containing basic functionality required by MDTP microservices, templates, patterns and best practices. The service teams build microservices using Play, Scala and Mongo. And they self-serve as much as possible using an “Everything as Code” philosophy:
- Want a new repository? Run a Jenkins job.
- Want a build pipeline? Add it as code.
- Want a logging/metrics dashboard? Add it as code.
- Want to configure your service? Modify code.
- Want a different alerting setup? Change it in code.
Let a 1000 flowers bloom tells us about Engineering Effectiveness. It pays more to make 1,000 engineers 2% more effective than making 10 engineers 50% more effective. At scale, delegating as much as possible to self-service is the only way to do that.
Take configuring secrets as an example: to ensure that secrets are stored securely, they need to be encrypted. If that encryption has to be carried out by a central platform team, then that implies some form of managing the flow of work. So a ticket has to be raised and triaged. Then a prioritisation call has to be made. Looking at numbers before self-serving secrets, on average it would take over 2 days to go from ticket raised to ticket closed (that’s hiding some outliers, the median was more like 1 day). Now it could be argued that engineers will factor in this kind of delay and not try to configure their services at the last minute, but it does form a bottleneck. And that bottleneck hurts the flow for an individual service team. It might only be a neglible delay, and engineers would be able to pick up another task while waiting, but a day here and there starts to become really noticeable when there’s 100 different teams. This is where the investment into self-service pays off. Not only does it increase the speed of getting things done for the service teams, it also frees up the bureacracy of raising tickets, adds accountability by auditing who changes which secret where and frees up the platform teams to smoothen the service developer journey further.
Trust But Verify
Now, after looking at the example of secrets management, you’d be tempted to think that giving teams lots of autonomy over everything would lead to ever faster turnaround time and better efficiency. That is a fallacy. Let me provide some context before making my point: When I first started out working on MDTP - a good number of years ago, I was working on a lift-and-shift service migration project that took legacy services out of an on-premise data centre and moved them into the cloud. In those early days I felt we were constantly at loggerheads with the platform teams. Couldn’t we have our own connectivity? Couldn’t we have our own Jenkins instance? How about an S3 bucket? No, no, no. I came to think of this as the “loving fist” of the infrastructure team, that very firmly said that it did not fit in with the opinionated way the platform was doing things. This was frustrating and created quite a bit of work for the migration to try to match the platform patterns as much as possible. I also have to note that looking back, the engineers running the platform were very pragmatic and tried to be flexible, but they knew that straying off the paved road too much would be trouble.
I came to really appreciate this when looking after those migrated services we had to often do a lot of extra work because we weren’t benefiting from the platform libraries and often had to retrofit functionality. I very much came to appreciate the opinions of the tax platform and am convinced that without it, we could not have made that migration a success - so much so that the yearly “Key Business Event” of Self-Assessment is now viewed as “Business As Usual” on the platform. Tax Doesn’t Have to be Taxing not even for platform engineers…
Back to my point and the catalogue! In order to ensure that the 100 teams and nearly 1,000 engineers that have got GitHub access don’t stray off the paved road and get into difficulty, the PlatOps team have made some tools to check on what the service teams are up to and provide specialist teams (UI, testing, AppSec, DB) that can provide expert assistance without each individual service team having to develop that expertise on their own.
Bobby
Bobby is a sbt plugin that checks dependencies against a list of banned and deprecated dependencies. This is used to ensure that teams cannot build services with dependencies that have vulnerabilities or known bugs or should no longer be used.
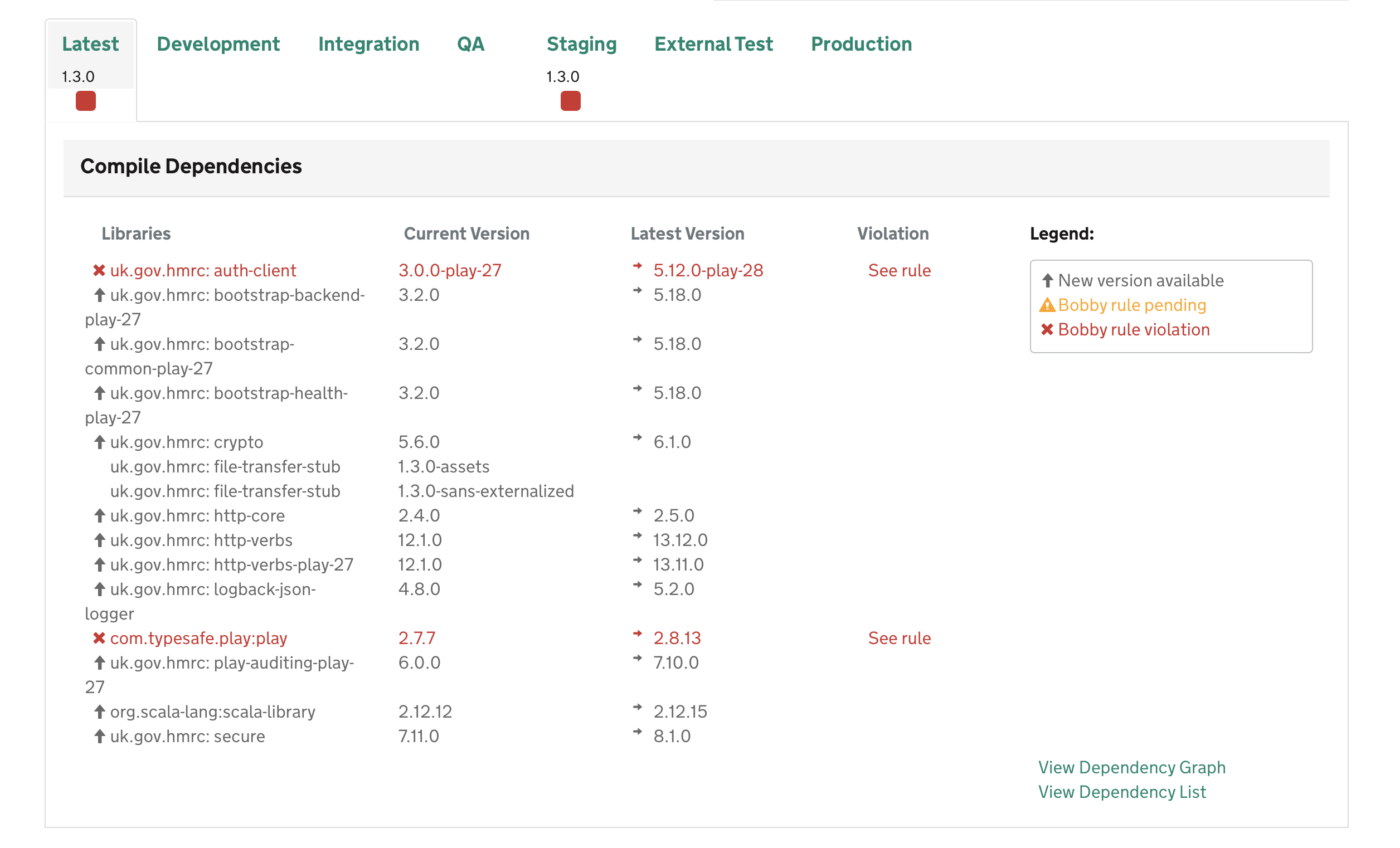
Dependency Explorer
The dependency explorer is a really important tool. To put simply, it allows to quickly find which service use which dependencies:
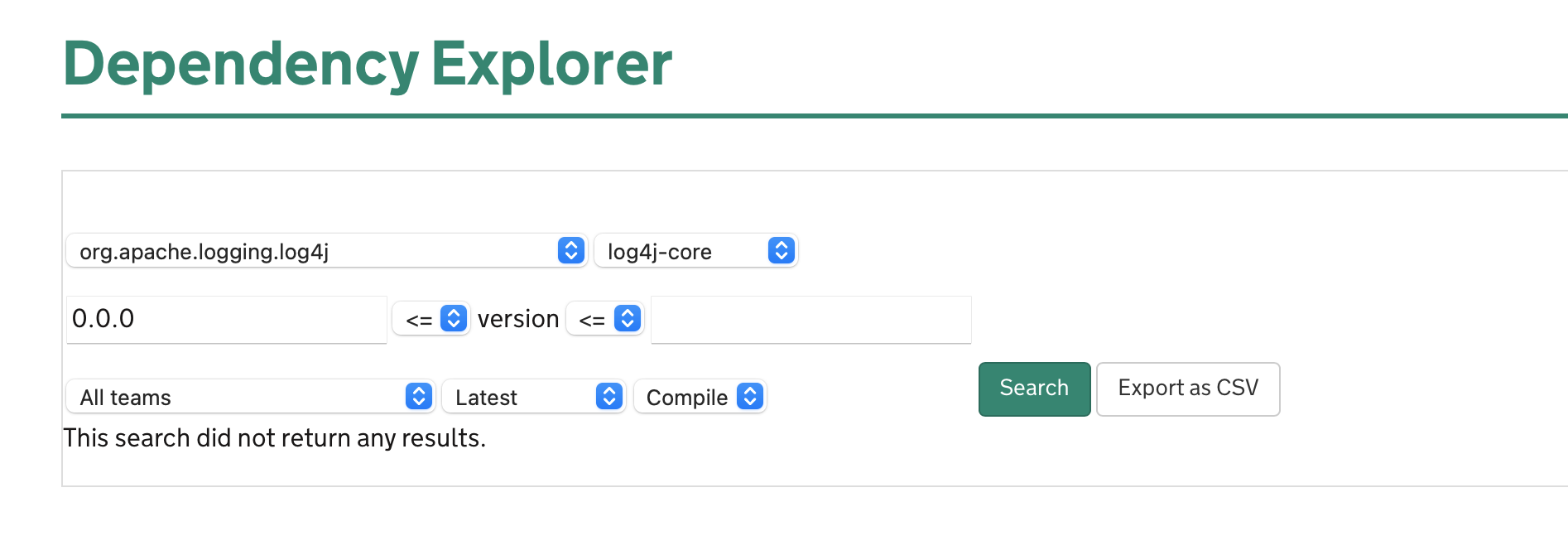
This is really useful when trying to find whether one of the 1,000 services is impacted by security vulnerability such as Log4shell or Spring4shell. Instead of scrambling around in GitHub repositories or unzipping jar files to find dependencies, the anxiety in MDTP about log4j dependencies lasted the best part of a couple of minutes when we breathed a sigh of relief that there weren’t any services that used it.
The dependency explorer is also very useful when trying to find old versions of a library, judging whether a component can be deprecated or whether there are too many users. That is useful for both service and platform teams.
How does it work?
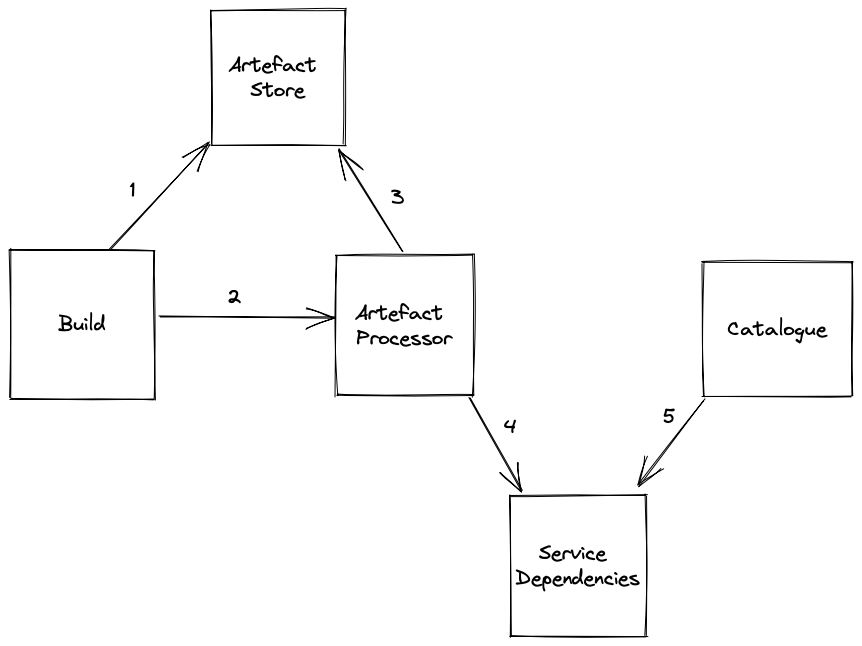
- The build system builds an artefact
- as part of the build, build metadata including the dependency graph are created and stored as artefacts
- bobby runs to check for dependency violations
- The build system puts a notification on a SNS topic
- The artefact processor service picks up the message and
- reads the metadata and dependency graph
- downloads the artefact and analyses the JAR files for dependencies
- The artefact processor stores the results in the service dependencies service
- The catalogue frontend uses the service dependencies service to visualise the dependencies
The build is kicked off on a commit and typically service teams have configured build pipelines to deploy automatically into the non-prod environments. So as soon as a developer makes a change, it gets built, gets analysed and surfaced via the catalogue.
Leak Detection
The leak detection component of the catalogue is primarily concerned with sensitive information leaking into a GitHub repository. As MDTP is very much trying to put code into the open there is always a chance that something sensitive leaks online. In order to deal with potential leaks at scale, the leak detection system analyses every commit to see whether any suspicious looking text are found:
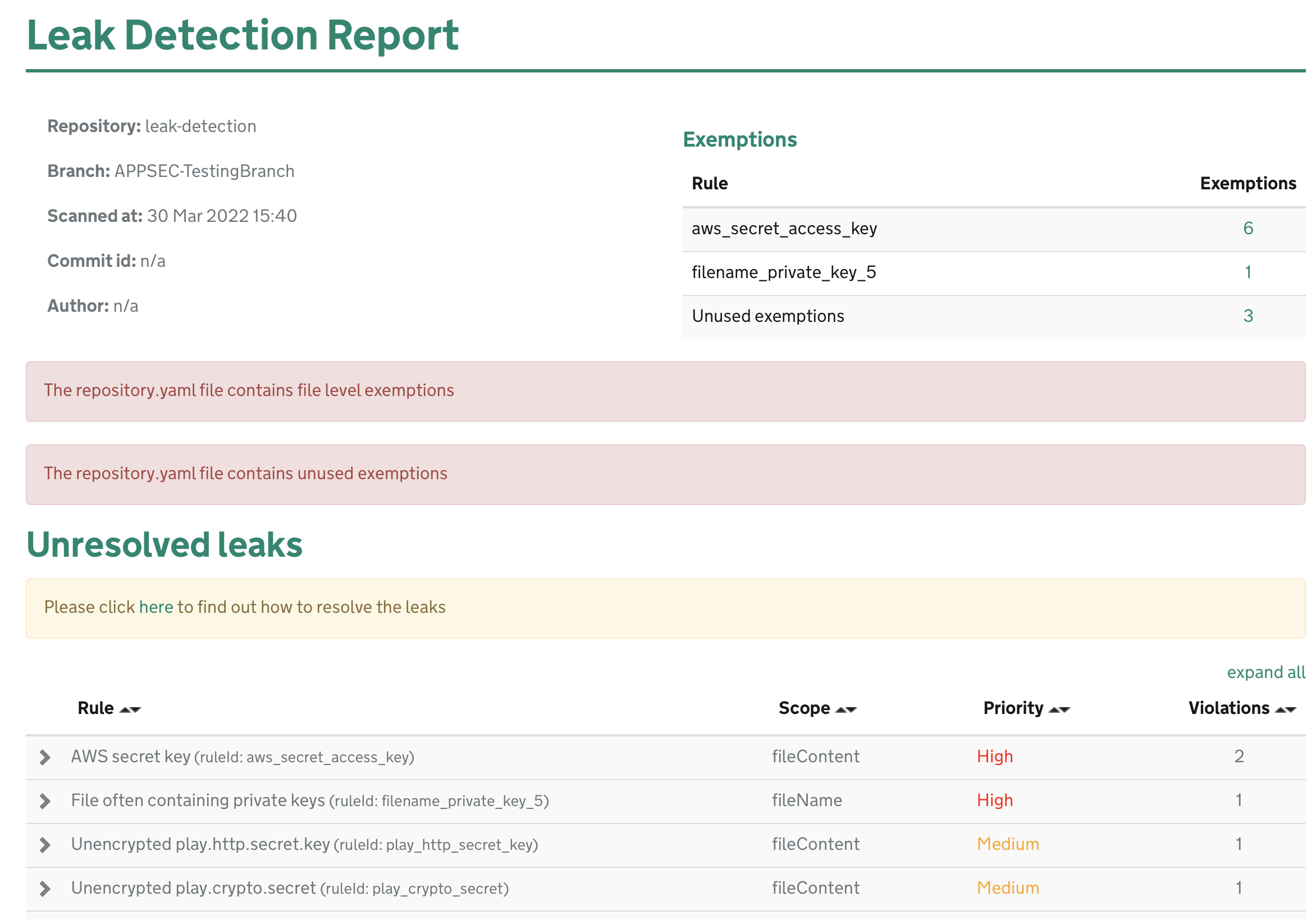
One of the lessons that we learned was that to be effective it needs to be really easy for service teams to provide exemptions to the leak detection rules and get visibility on whether those exemptions are used or not. If teams cannot resolve false positives quickly, then what tends to happen is that the warnings will get ignored. If warnings regularly get ignored, then AppSec engineers have to start chasing teams and that just does not work at scale.
Slack Notifications
Slack plays an important role in MDTP to communicate with teams quickly and efficiently, not only instantly but also asynchronously. I talk more about the importance of Slack in Making Software. Quickly but one of the important was that the platform communicates with teams and engineers is by automated Slack notifications.

Notifications are used to
- notify of build failures
- notify leak detection alerts
- notify shutter events
- notify deployment events
- notify security events
- alert failing services
- security alerts
These provide an important feedback mechanism for engineers to go and check if something is odd. As often is the case, if the alerts are too frequent or don’t go in the right channels, they can be at best distracting and worst just get ignored. It is really important to get metrics on how these alerts are used. But here’s a thought, just keeping track of when what Slack notifications get sent to whom provides an interesting amount of observability.
Conclusion
It cannot be overstate how important having the catalogue is to the ability of MDTP to operate at scale. As an AppSec platform engineer, I cannot begin to imagine what a nightmare the log4j incident would have been if we had to have chased down 1,000 microservices' worth of build files to determine whether we were vulnerable or not, or having to rely on almost certainly out-of-date contact information for teams on some wiki page that was last edited 3 years ago only to find out that most of the engineers had moved on. It would be a lot of work if we had to keep searching through the source code to see whether there are any hardcoded passwords or auth tokens. It is pretty clear to me that any digital platform that operates on a non-trivial scale absolutely needs a catalogue.
It doesn’t have to be a purpose built one - when the MDTP Catalogue was first built, things like Backstage did not yet exist and it does not have to be all singing all dancing. But if your platform cannot tell you who is responsible for a service, what components is it using, where is it deployed, who deployed it then you’re flying a little bit blind.
Tags agile tools paved-road catalogue digital-platformIf you'd like to find more of my writing, why not follow me on Bluesky or Mastodon?