Curating Dependency Vulnerabilities
- 8 minutes read - 1604 wordsIn this post, I am going to look at an increasingly important part of securing applications: Your supply chain. This includes every library, tool or service that you are using to build, run and monitor your service.
When the log4shell vulnerability hit, it wasn’t just a matter of looking at the dependencies that your source code pulls in, but also at the infrastructure you’re using and the build pipeline.
Have you had a look at the vulnerability reports of your dependencies lately? Did you like what your saw? I didn’t at first. Here’s what I saw at a tax collecting agency in the UK where I work in AppSec:
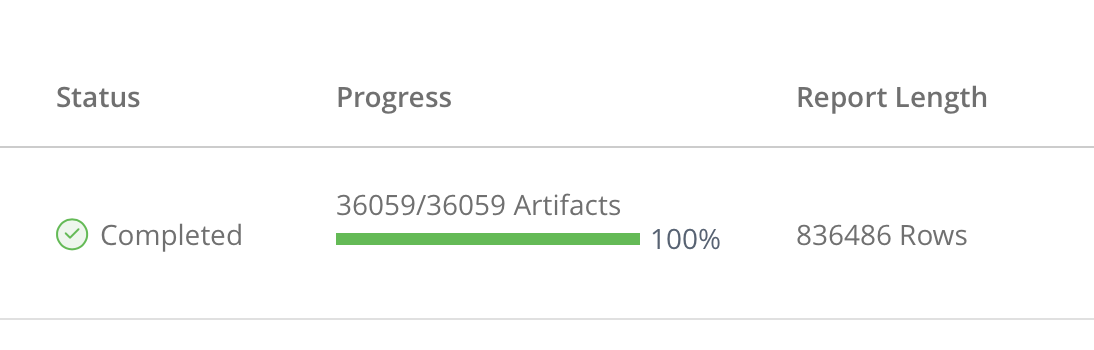
Now, I will admit this X-Ray report contains a bit of hyperbole. Yes, it is a screenshot from X-Ray but 36,000 artefacts contain current as well as older versions of our services. In actual total, there are about 1,000 microservices in production and about 100,000 reports to consider, which encompass 1,000 different dependencies with 1,300 different CVEs (Common Vulnerabilities and Exposures).
How am I ever going to analyse that?
CVEs have got a CVSS (Common Vulnerability Scoring System) score of 0-10. Plenty of people (and tools) use this score to allow setting up of policies. For example:
- Prevent any builds of where CVE scores greater than 8.5.
- Warn if there are any builds with CVEs greater than 7.
And so on. But is that actually any use? My instinct has always been that the scores are too broad an indication. A CVSS score of 7.5 does not mean it is less dangerous than a CVE score of 9 or necessarily less of a priority. The scoring system is an way of trying to categorise problems in some very broad categories. Have a look at the CVSS calculator and the CVSS metrics to get a feel for how broad a score is. There also is the contention that since having a CVE on your CV is profitable for security professionals that some vulnerability scores get a little overegged. For a much more detailed critique of vulnerability scoring can be found here. That essay made me wonder about the distribution of CVE scores at my client (more on that later).
I seriously would not recommend trying to look at all CVEs all at once (the 100,000 reports I mentioned earlier) because it just gets too overwhelming. Also, while the data that is contained in X-Ray reports is really useful (amongst other things it contains good descriptions and references), their UI is not fit for purpose. If I wanted to look at a report it would look like this:
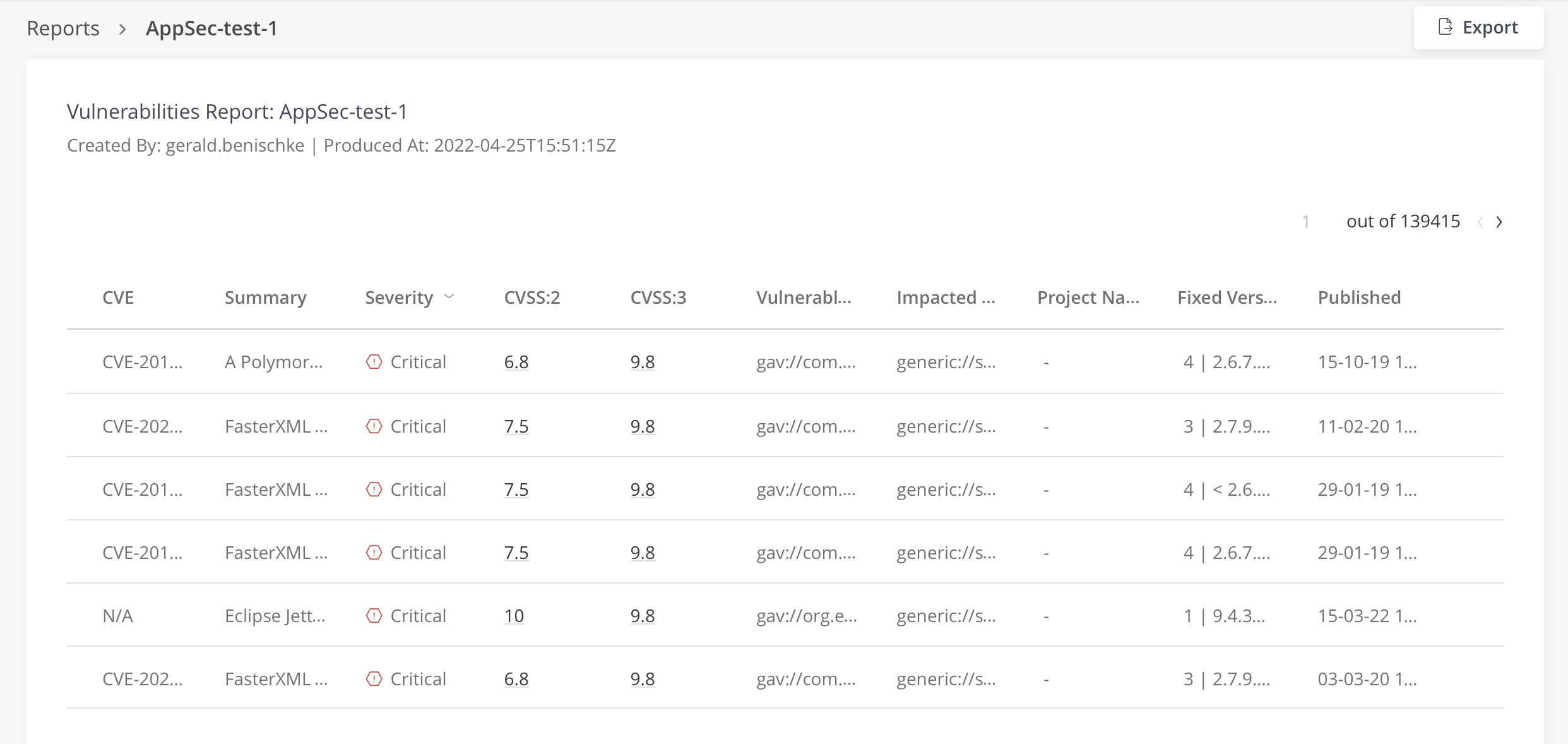
There’s a long list of 139,000 pages - with pretty much every column only readable by hovering over fields to look at tooltips. Maybe this works when you have a stack of ultra-widescreen monitors, but I happen to work on my laptop a lot and just cannot use the X-Ray UI for reports.

APIs to the rescue
Fortunately, X-Ray provides a nice REST API to generate and download reports. The API also helped me around limitations of the X-Ray exporting where it stubbornly refused to generate JSON reports with more than 500,000 results. I was also immensely helped by the fact that I am working with a platform that has a great service catalogue, so I was able to integrate getting the list of deployed versions in production with the report generation.
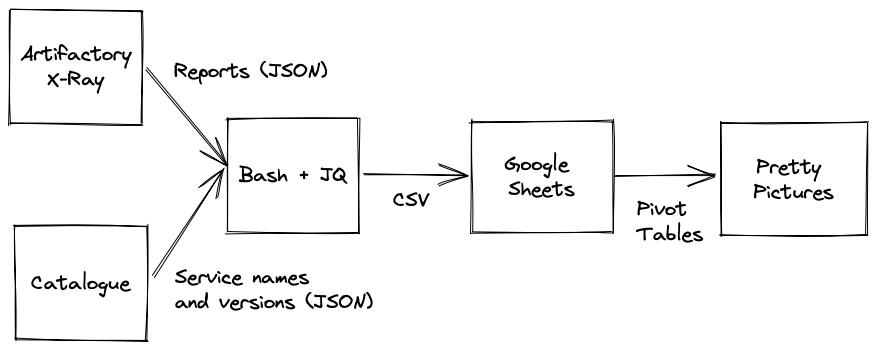
Next was to realise that the reports I got from X-Ray are raw. Without context, they do not tell me anything. It is pretty pointless knowing that I’ve got 800,000 reports across all the services on the platform. I did not need data, I wanted information.
With the raw data, I created the following reports:
- Every week, I extract the version numbers from the platform of services that are deployed using the service catalogue
- From that I generate X-Ray reports which gives me a list of CVEs and how many times they recorded - that gives me a view of vulnerabilities as they come in. This is done using a JQ script to avoid having to create a pivot table with tons of rows.
- I can sort by number of occurrences, score and more.
This gives me a focus on which CVEs to look at first. Having an opinionated platform helps (see Making Software Quickly for more details), because strong opinions mean that the amount of different patterns are limited - well, in theory anyway.
In practice, at the tax collection agency those 1,000 microservices end up pulling in over 3,600 different dependencies (and that’s JAR files alone). But at least, the platform does not support lots of different languages and frameworks. In my view, these opinions create guard rails and a paved road. And in case of AppSec work make life a lot easier.
To illustrate my point: if every one of the 100 teams that look after those 1,000 microservices reinvented every pattern, there would not be any synergies. With strong patterns and guard rails, a centralised AppSec team that focuses solely on finding problems across the platform and keeping an eye on security trends becomes feasible. Without that centralisation, it would be very expensive to have security experts on every team. But I digress, I promised to talk about CVE score distribution earlier on:
Scores - more scores!
After a few weeks of looking at each CVE individually, weighing up the descriptions against my knowledge of patterns on the platform, I was able to decide which CVEs could be ignored, and which ones needed further investigation.
Let’s look at a couple of graphs. An interesting picture emerged. First of all, let’s look at the distribution of CVE scores (fig 1):
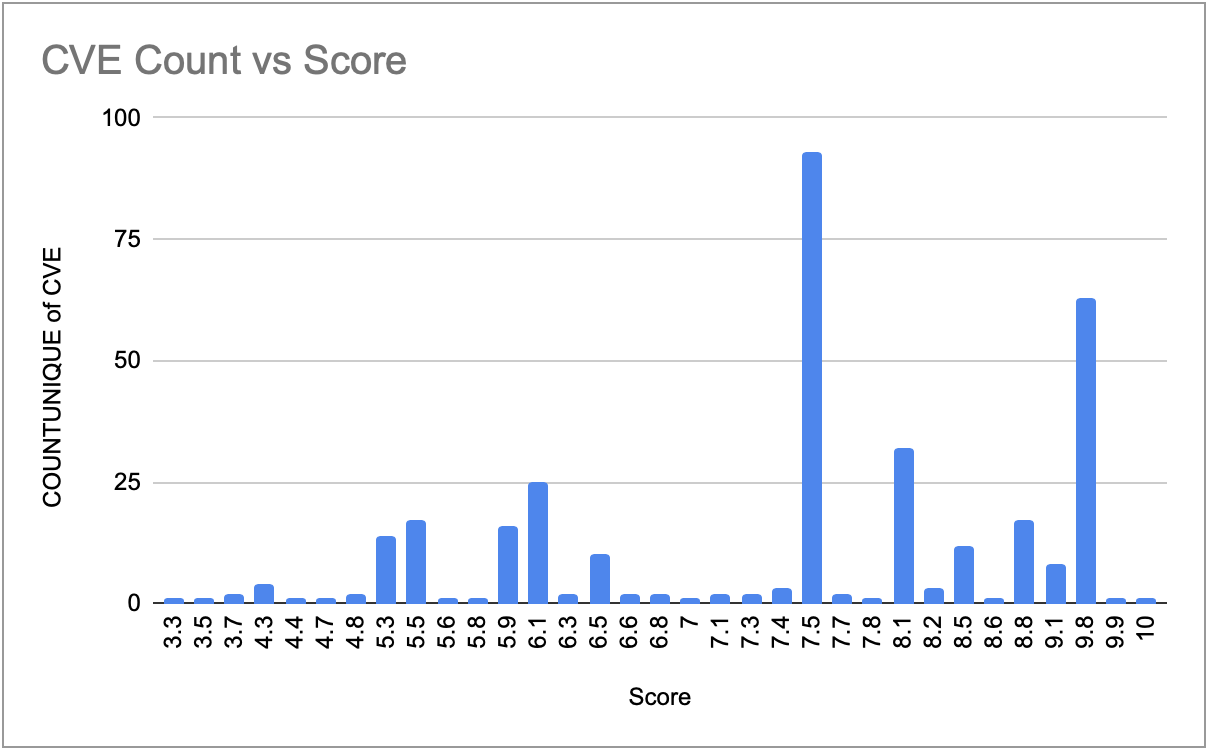
The interesting fact is the peaky nature of the distribution and validates the findings by Jacques Chester. Please do resist the temptation of looking at CVE scores as a continuous value where a score of 7.5 is 2 units “less worse” than a CVE score of 9.5.
My next graph tells the another story. Out of over 300 CVEs, I determined that 200 needed no action, and 100 needed further in-depth investigation. Note, this does not imply finding an exploitable vulnerability, just that from the description alone it couldn’t be ruled out whether there is something that needed attention or not (fig 2):
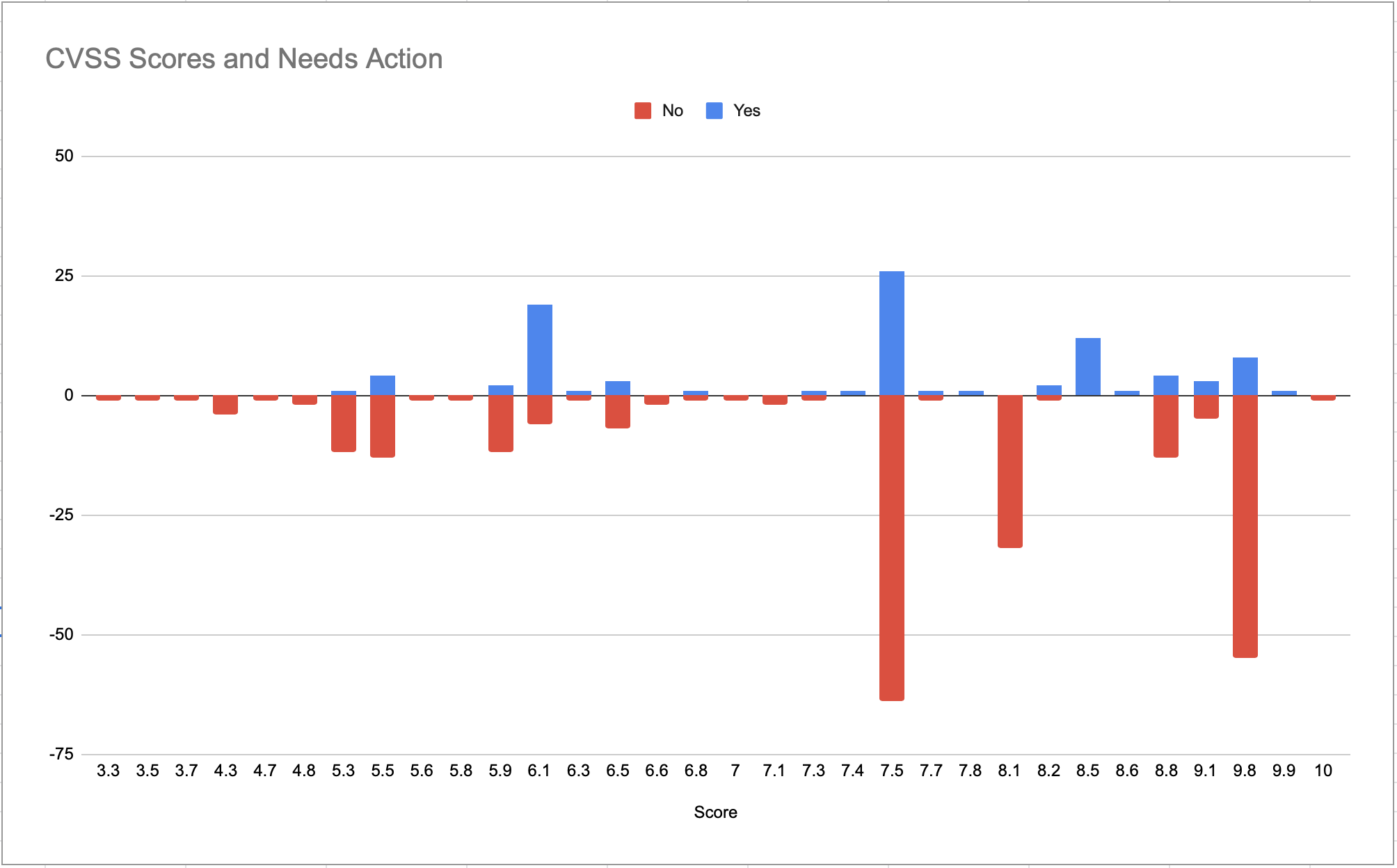
Looking at the above graph (fig 2), the CVEs that resulted in further investigation are in blue above the centre line, the ones that weren’t considered actionable are in red below the line. From that snapshot it does not look like there is a correlation between CVE score and whether it should be actioned.
Anecdotally, this is something that I have always felt. I have seen CVEs with score 10 that were not applicable due to the context required to make it exploitable and CVEs with score 7.5 that can take down a service in a single request. The only conclusion from this is that, unfortunately, policies that just use the CVSS score to determine whether a dependency should be blocked or not is only going to give you a false sense of security.
Let’s dig into the stats a bit more. By getting the raw data in JSON format and extracting information in it, I was able to look into which components/dependencies provide the most value in terms of spending effort investigating (fig 3):
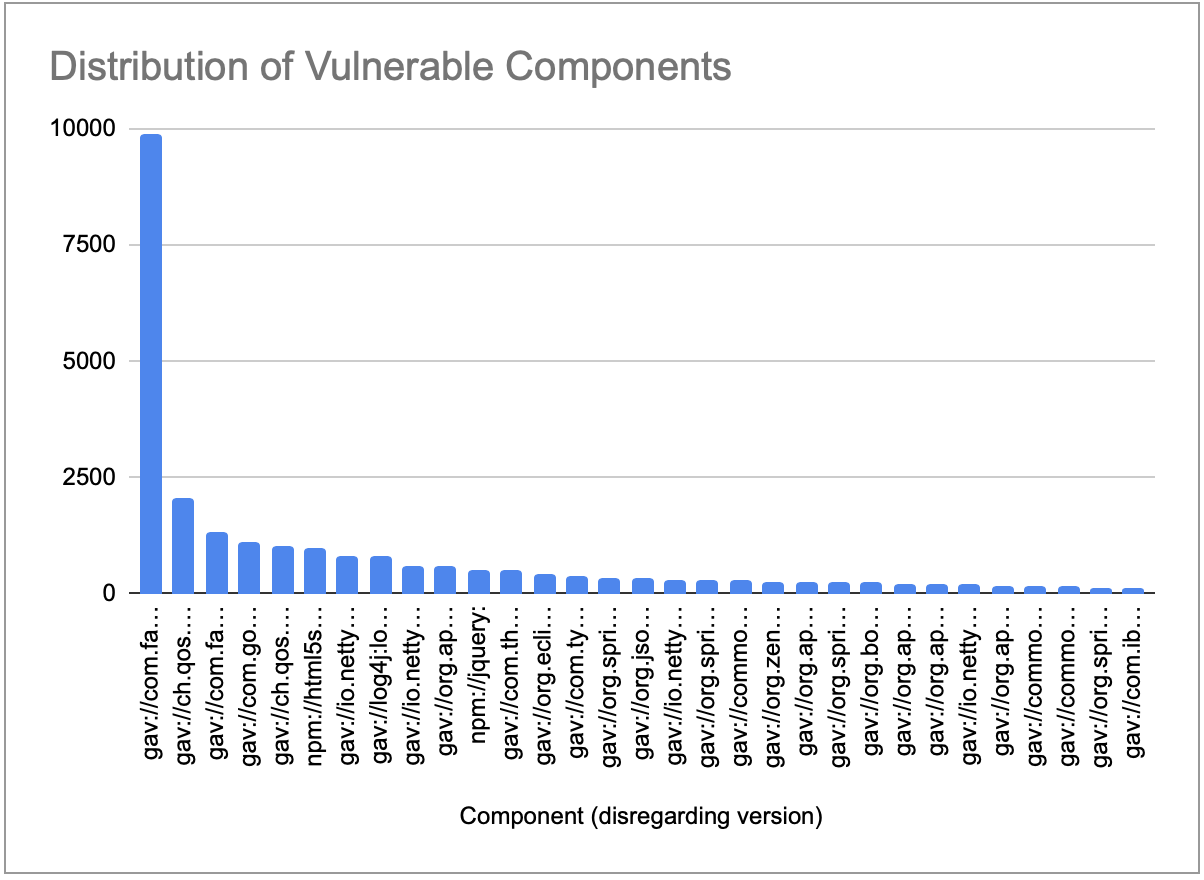
The above chart is showing there is a concentration of CVEs at a impacting a few specific libraries (the above shows total occurrences). Again, don’t be fooled by numbers - after my analysis of the CVEs, looking at whether they were actionable vs not-actionable paints a slightly less scary picture (fig 4):
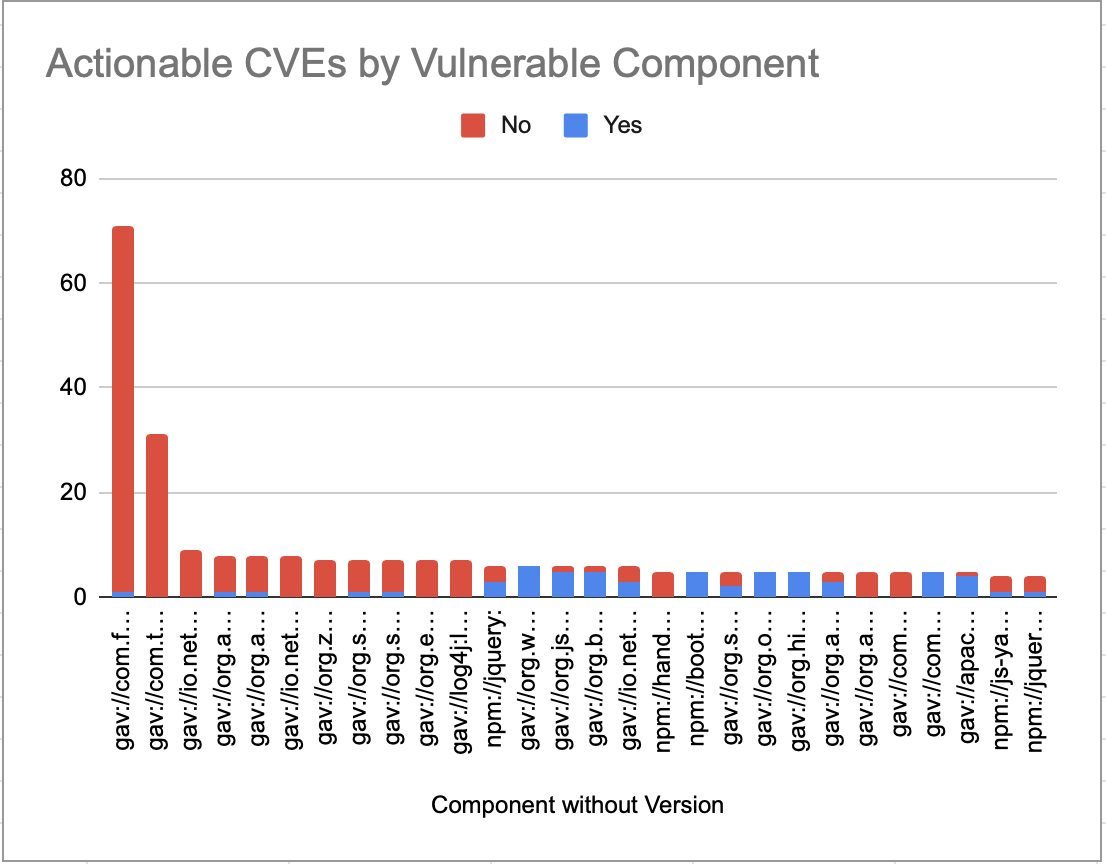
It appears while some components have got lots of CVEs associated with them, the actionable ones are not necessarily the most frequent ones.
Important Caveat
Please note, these numbers are not to be used to make sweeping generalisations. I’m not saying that the high CVSS scores should be ignored in favour of lower ones in general. Yet, I found it very interesting that when I put context around the CVEs, different pictures emerge.
Conclusion
My recommendations when working in the AppSec space and looking after vulnerabilities is to ensure that you turn data into information. It’s no good rushing to tell development teams about every vulnerability, because at scale that’s impractical. For me, the humble spreadsheet, has been invaluable.
- Try to categorise your CVEs!
- What are the most frequent vulnerabilities?
- Which ones have the highest scores?
- Can they be exploited?
- What type of vulnerabilities are the most common? (CWE (Common Weakness Enumeration) could be useful).
In short, try to build a picture of what is going on in your system. It really helps if you know the code, and know how teams operate. Knowledge of and familiarity with the codebase is very important, so be prepared to read a lot of code and a lot of CVE descriptions. Knowledge of your infrastructure is also really important. WAFs, VPNs and engress protection can turn a really scary vulnerability that drops on a Friday afternoon into something that can be dealt with calmly on Monday morning rather than working frantically through the night/weekend to remediate.
I was struck by Michael Brunton-Spall’s 200th Cyberweekly newsletter. The value is not in producing the most links to Infosec stories in a week, but to pick out and prioritise the most interesting ones. Like a curator. When looking for vulnerabilities it is the same story. A story of prioritising anything - you need context to know which are most likely to cause problems for your system, investigate and fix accordingly.
Tags appsec agile security catalogue digital-platform cve spreadsheetIf you'd like to find more of my writing, why not follow me on Bluesky or Mastodon?