Making Software. Quickly.
- 8 minutes read - 1681 wordsIn this post, I describe my personal experience of being part of a software development team working with Equal Experts and HMRC during Covid-19. Under normal circumstances, we’re responsible for tax services such as Self Assessment, PAYE Expenses and Benefits, VAT submissions amongst others. These services run on the Multi-channel Digital Tax Platform (MDTP). This platform is hosted in a hyperscale cloud (the cloud provider has a sideline selling books), run in-house by HMRC teams made up of permanent staff and consultants.
When the UK locked down during Covid-19, this platform enabled HMRC to turn around big projects very quickly. The Coronavirus Job Retention Scheme (JRS) went from inception to production in 4 short weeks and the Statutory Sick Pay Rebate Scheme (SSPRS) and the Self Employed Income Support Scheme (SEISS) came not long after.
The numbers were staggering, this was the dashboard after a single day of JRS
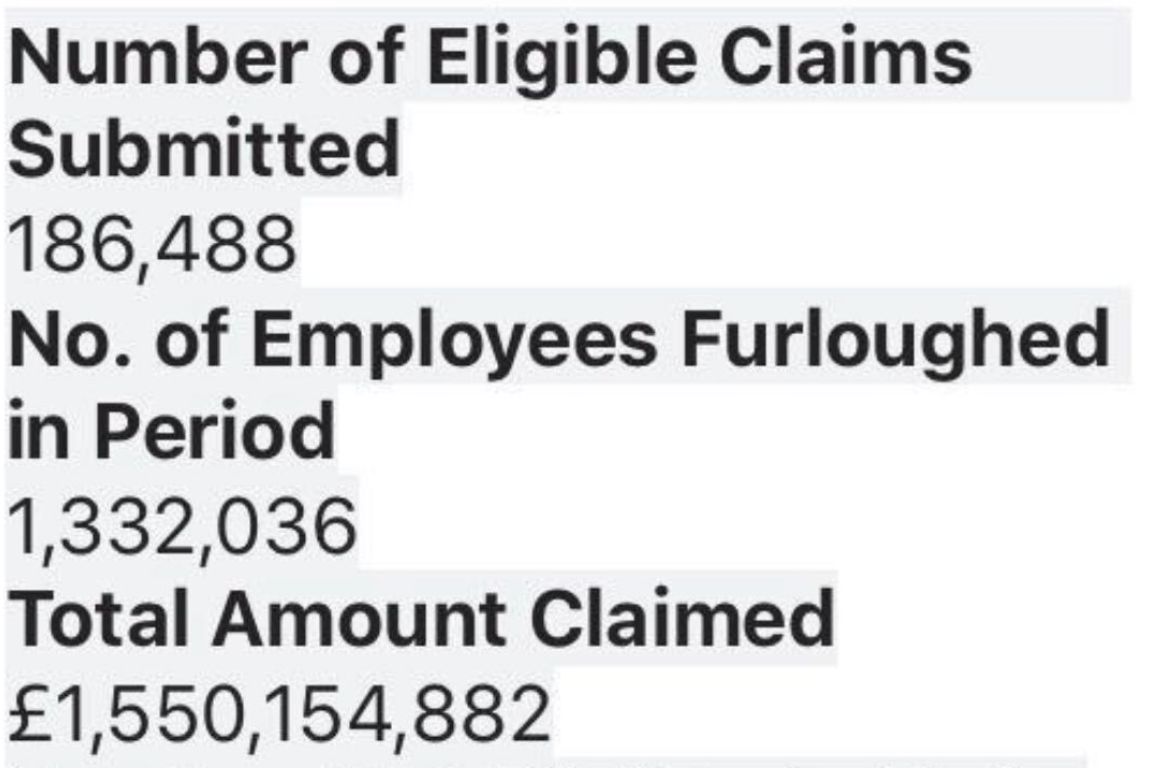
And SEISS was even bigger on its first day…
Equally impressive were the customer satisfaction stats
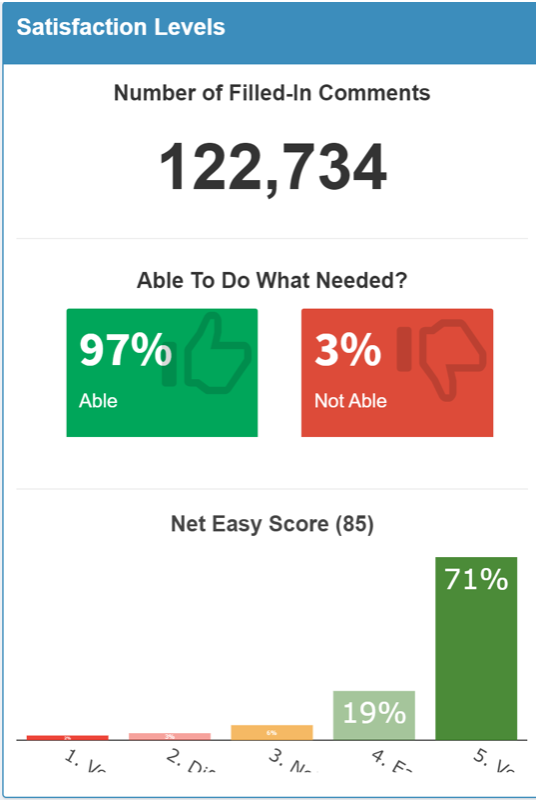
From my point of view, the effort that went into delivering these systems was nothing short of miraculous. There were dire predictions about “surely, the website will crash” - when that didn’t happen, the social media doom-mongers were predicting that “there will be problems with payments”.

But no! 4 weeks after the Chancellor of the Exchequer announced the schemes, a whole new system was designed, implemented and delivered. And it just worked.
A number of suppliers were involved in creating these systems. I played my part by creating new services at very short notice. But nobody would have been able to move at the pace that we did without standing on the shoulders of the Multi-Channel Digital Tax Platform (MDTP).
Impressive stuff. But how, do I hear you ask? But before I answer that, a bit of context.
Background
I’ve been part of the Manchester team for about 3 years. The project started with the “rehoming” of legacy services where we moved Weblogic J2EE web applications from a data centre into MDTP.
As such, my experience with HMRC code started by trying to understand millions of lines of code of monolithic applications.
Note, we didn’t rewrite or refactor - we wanted to move it into the cloud and just make it work. The improvements came
later. While it is not as exciting as greenfield development, and involved the occasional head-against-brick-walling -
it was quite satisfying to move applications out of the data centre.
Following that, I was also involved in the Data Tier migration, whereby we shifted Oracle databases out of the data centre and into the cloud. This will become important later in the story.
When I started, I think it is fair to say that these legacy services were considered a bit of an aberration. We were using 13-year old Java code with Oracle, the rest of the MDTP platform were on Scala services with Mongo data stores. This meant that our services needed a lot of special treatment as our stuff didn’t work in the same manner as all the other service. And that created friction. Especially as MDTP is an “opinionated platform”. This means that there are certain ways of doing things, and the platform teams are very careful to “guide” the service teams to ensure that everyone follows the same patterns, concentrating more on solving business problems, and not technology problems. In practice, this meant requests for different types of infrastructure were very often met with a stern “No”. At the time this was frustrating, but I quickly came to understand that this is with very good reason. I do not believe that it is possible to support over 150 teams and 1000 microservices and billions of HTTP requests on peak days by letting every team do whatever they like.
The Art of the Possible
Even though “the art of the possible” is a phrase I’ve come to loathe (as it increasingly gets overused), at those heady days of running at 110%, working weekends and all hours, it seemed very apt. Note, I worked those hours not because I was asked, but because I wanted to help. I know I’m not the only one who put in lots of hours to support getting these HMRC-opens-the-money-taps schemes out of the door.
The most important aspects of delivering a system at breakneck speed is the ability for engineers to be able to just get on with it. I’ll list what I’ve come to regard as the most important aspects of moving quickly at scale
Ease of Communication
In my opinion, first and foremost are good communication tools and practices. At HMRC Digital heavily relies on Slack. It is very easy to have instant conversations but also keep track of what happens elsewhere.
A Slack channel could be created ad-hoc for a specific issue. Engineers, analysts and designers from multiple teams and specialisations can focus collaborating and solving problems without endless meetings or endless email chains.
If there are any questions for a specific team, asking on their public team channel is the first option and usually gets a quick response. Private Slack channels are internal to teams - so the day to day internal discussions do not get aired in the public. There are also community channels. If I have a question about Scala, I can go to a community Scala channel - if I’m stuck on a performance testing issue, there’s always help available in the testing community channel.
There are thousands of channels - a consistent naming convention and good channel descriptions are essential, otherwise it becomes unmanageable.
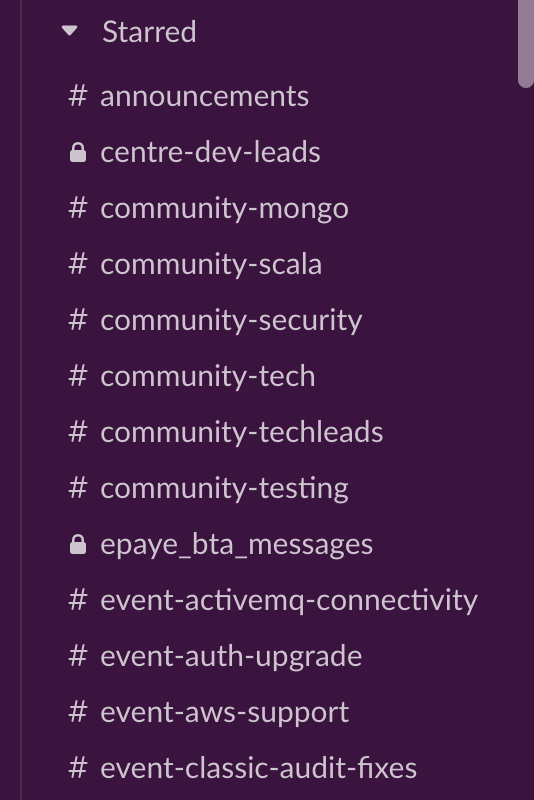
If I were to imagine trying to organise as many subjects and conversations via email, the HMRC Covid response would have been an abysmal failure.
Back to the story!
I was following a Slack channel where the Covid-19 services were discussed and a concern popped up about a part of the sign-in journey for tax agents. The predictions are that a call-out to a backend system that still sat in the on-premise data centre could be too slow. I did a little thinking and suggested that instead of calling the data-centre we could just look up the same information in the databases we migrated as part of the data tier migration mentioned earlier. The trouble was that there was no microservice, and the changing the calling service to accommodate Oracle database connections was non-trivial. And this was only about 4 days before everything was going live. So I would write a new service. This happened on the back of a Slack conversation. One amazing feature of the breakneck speed of the Covid-19 response was that regardless of supplier - or where the funding would eventually come from - people worked together seemingly crossing supplier and team boundaries with ease.
Self-Service + Infrastructure-as-code = Speed
The other really important aspect of working at speed is that as much as possible can be achieved using self-service.
In order to create the service I mentioned above, I needed to
-
Create a new GitHub repository - that is done via a job on the build server - takes less than 2 minutes. There are a few templates available, so I picked a “backend” service, which created most of the boilerplate code of the service for me. The boilerplate includes things such as sending metrics to the metrics backend, authentication for incoming requests.
-
Create new build pipeline. The pipeline is defined using a Domain Specific Language (DSL) in the build jobs repository. To create a new one, I created a pull request and a few minutes after, I had a pipeline that would build, test and deploy my service to the development, QA and staging environments.
-
Create some test scripts that create the database schemas (this would allow me to have the test database locally as well as using it for testing on the build server), this is defined “as code” in the service repository.
-
Create configuration entries - more Pull Requests
-
Create a kibana dashboard for accessing logs - Pull Request
-
Create a grafana dashboard for accessing metrics - Pull Request
-
Create alerting configuration (so that if something goes wrong I get woken up by PagerDuty) - another Pull Request
Within next to no time, I had all the supporting components in place. Logs, performance monitoring, automated alerting, a build pipeline that would automatically build and deploy to the non-production environments as soon as I committed to the main branch. It would even configure a Pull Request Builder that would run the tests before committing to the main branch.
All this was done in a matter of minutes, giving me time to focus on writing the service itself.
This is where I can stand on the shoulders of the MDTP Platform Teams:
- The Build and Deploy team have provided the infrastructure and DSL to allow me to define my build pipeline in a matter of minutes.
- The Telemetry team allow me to view logs and metrics. I don’t need to know that in the background there’s a complex
telemetry infrastructure that ingests logs via Redis and Logstash and then makes it available to ElasticSearch/Kibana.
All I have to know is that I get a dashboard that gives me all the requests and errors (and downstream calls…) - The Infrastructure team look after all the infrastructure (load balancers, proxies, security groups, databases)
- The Security team ensure that all the patterns applied are secure and provide practical guidance on any matter
- The Transaction Monitoring team keep track all the requests/responses
If I am interested (and I frequently am) I can see all the components infrastructure source code, but I don’t have to know how it’s built to use it.
And doing it at Scale!
I cannot repeat often enough how impressive a feat delivering these service were, considering we’re not talking about a small start-up. This is a big government department, with a multitude of suppliers, hundreds of teams and thousands of engineers. But in terms of agility and can-do culture, HMRC is a great place to be, with a pool of very talented people and a culture to match.
Tags agile covid-responseIf you'd like to find more of my writing, why not follow me on Bluesky or Mastodon?