One million records in 15 seconds
- 6 minutes read - 1114 wordsIn this post, I’d like to talk about optimisations that I recently used to provide a Scala Microservice that surfaced payment events. The events were held in an Oracle backend and the Microservice was in a docker container with (1 vCPU) allocated 512MB to the container and 256MB to the JVM that was running it. In this writing I’m not going to talk about the Oracle optimisations to make the underlying query fly but rather would like to concentrate on the kinds of things that can make service code quick.
First Iteration
I’ve implemented my fair share of microservices that surface a SQL Query as JSON during my time. Using Scala is making this rather simple.
I would have a repository class dealing with JDBC - in this instance we’re using Stored Proc, so Slick or Anorm were of limited use here - hence straight JDBC:
|
|
And there would be a controller
|
|
Simple enough, but not very effective. When pushing the service to surface 10s of thousands of records, it struggled.
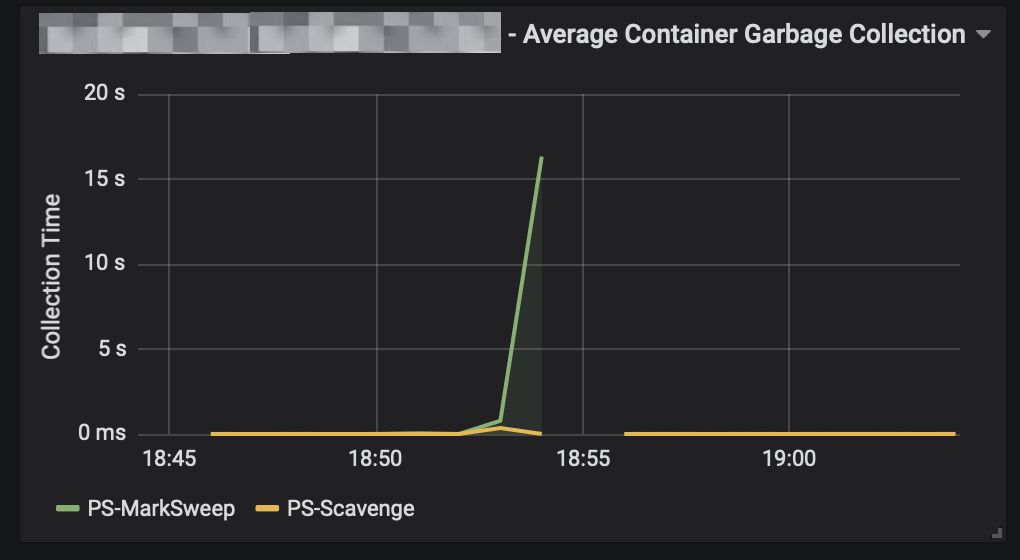
Spending seconds in the garbage collector sure was a clear indication that we were running out of memory.
Optimisation: Use Streaming
My hunch was that creating a big List[PaymentEvent] all in memory and then transforming it all into JSON
in one go wasn’t very good. It would be so much better for memory and performance if I could “stream” the
response. I.e. start sending JSON responses down the wire before the DB query had even finished. Fortunately,
Play/Scala is rather good at it - if only a little less staightforward.
First off, we change the code that accesses the stored proc:
|
|
The main change is very subtle. .toList was changed to .toSeq - but there is a world of difference. When calling
.toList on an Iterator, all the elements of the iterator are turned into a list, whereas .toSeq is lazy - which
means that the iterator is worked as and when elements in the sequence are needed. This means that after the method
returns, it hasn’t actually iterated over the JDBC ResultSet yet. Furthermore, the following controller changes all
the results to be “streamed” - (Play is built on Akka Streams)
|
|
Instead of transforming a whole List into JSON using Json.toJson, here we are sending “HTTP chunks” as responses,
which means that we can start sending the response BEFORE we’ve finished building it.
Stepping through the code:
Source.fromIterator(() => ...)will use the sequence and iterate across it and create a stream of PaymentEvent objectsresult.iterator.map(r => ByteString(Json.stringify(Json.toJson(r)))turns an individual PaymentEvent object (i.e. a DB row) into a binary representation of a JSON stringintersperse(...)will create the array event that PaymentEvents did in the original code (we’re returning an array)alsoTo(Sink.onComplete(_ => callback.onComplete()))will be called when the streaming finishes to close the JDBC connection Note, none of those steps actually happen untilOk.sendEntity(HttpEntity.Streamed(source...))gets called at which point Akka takes over and “materialises” the stream as it is sent down the wire. During my investigation this worked rather well. I pushed the service to return half a million records in 14 seconds with curl measuring the output:
|
|
Not bad! But we could do better
Optimisation: Bigger Fetch Size
I was able to optimise the query further (500,000 records in 8 seconds) by tweaking the JDBC connection settings
hikaricp {
[...]
dataSource {
defaultRowPrefetch = 1000
}
}
By default the Oracle driver fetches 10 results at a time - which will result in 50,000 network roundtrips - by changing
the defaultRowPrefetch property on the connection, it would fetch 1,000 results at a time, reducing the number of
network roundtrips.
Optimisation: Iterator instead of Seq
I wanted to to push the service again, and found that when I asked it to load 1 million records - it fell over
|
|
So something wasn’t streaming!
I fired up “jvisualvm” and did a heap dump locally and found
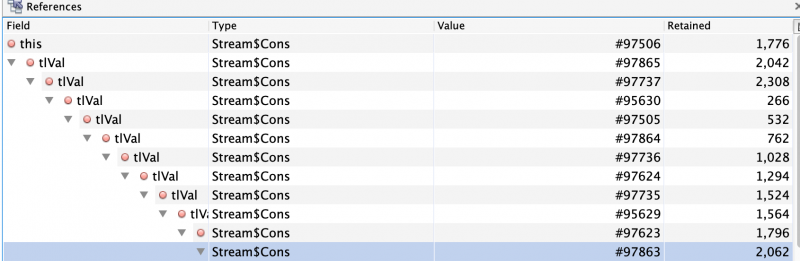
What was happening here was that the “lazy” Seq wasn’t as lazy, but hanging on to an initial reference. Further research gave me the following: https://pedrorijo.com/blog/scala-streams/
So I replaced the toSeq with using an Iterator directly:
And then I retried to run my query for 1 million records - and while it was quick, it wasn’t working properly. Half the records were missing.
It turns out that using the iterator like I had was a problem:
|
|
The contract for Iterator states that hasNext should not have any side effects. And my initial implementation
DID have side effects. It moved the JDBC ResultSet to the next record. But if I called hasNext twice (which is
exactly what happens when Akka streams the response), I’m skipping records.
So the final task was to create an iterator that would fulfil that non-side-effect contract:
|
|
Running the performance test 1 million records arrived back safely:
|
|
and the memory stats? Hardly touched:
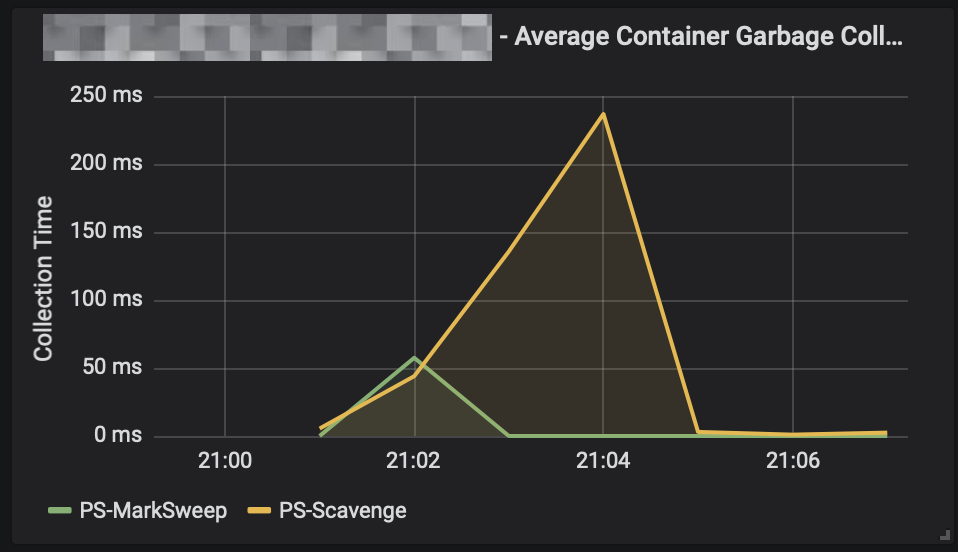
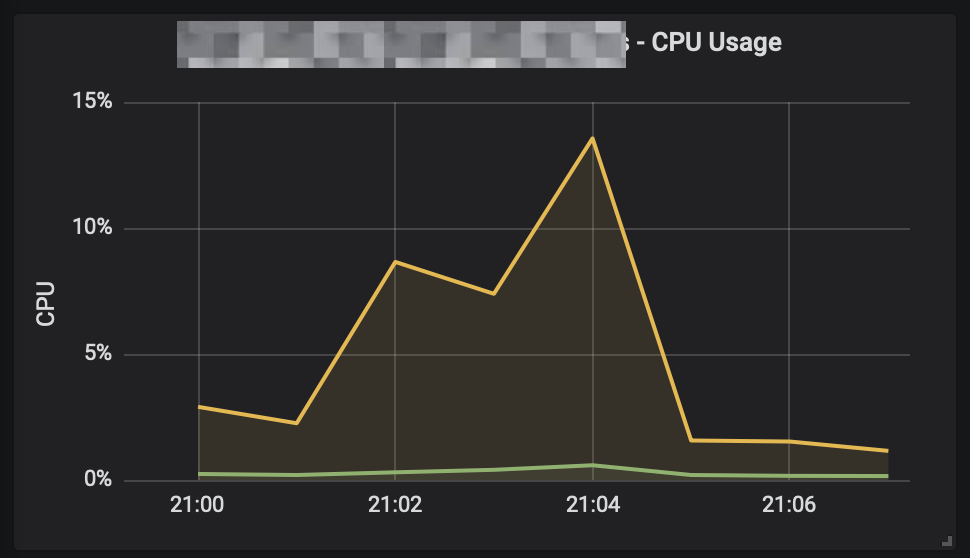
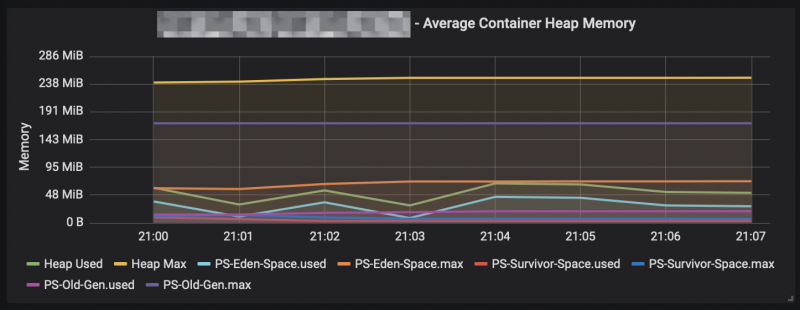
Conclusion
When dealing with big responses (or requests for that matter) - it does not necessarily need lots and lots of RAM! Using the right approach (streaming results and setting sensible fetch sizes) can make a big difference.
Tags performance scala oracleIf you'd like to find more of my writing, why not follow me on Bluesky or Mastodon?